“Building software” is a phrase I hear used time and again. Indeed, many do still think of software development as akin to construction. Modern (agile) software development doesn’t feel like that to me. There was a time, like the construction architect, when we had to increment and iterate on paper and in models. The cost of computing was too high to do such iteration inside the machine. The cost difference between making a small change in our understanding and reflecting that in the actual product was too great. The cost of change meant that we had to treat the creation of software like constructing buildings or bridges. But those times are, or should be, in the past.
To me, modern (agile) software developmentfeels more like pottery. But, instead of ‘throwing clay’ we throw our consciousness, in the form of electrons flowing over silicon, onto a spinning wheel of user-story implementation cycles.
We evolve our understanding of what our customer wants with each conversation. We reflect that understanding by evolving the product’s shape as we touch the outer surface with each new automated acceptance test (or example scenario). We evolve its structure as we touch the inner surface with each new unit test (or unit specification). We keep it supple as we moisten it with each refactoring. Our customer looks on, gives us feedback and we start the next revolution of the software development wheel. Never letting the product dry and harden; keeping it flexible, malleable, soft(ware).
There is nothing that feels like construction here. I never feel like I’m “building” something. Much more like I’m evolving my understanding, evolving the product, evolving my understanding again and so on.
For these reasons l am not comfortable with referring to this process as “building”. I’m also not comfortable calling it “throwing” (as in pottery).
I am very comfortable calling it “development”. I use the word “develop” in terms of its literal meaning:
“to bring into being or activity; generate; evolve.”
–dictionary.com
From the first thought of a new idea, through each conversation along the way, to each revolution of the software development wheel, I develop products.
I don’t “build”.
I create. I make. I shape. I evolve.
—————————
Footnote: I’m not aware of anyone drawing this analogy before. If you have heard or read someone explain it in this way before now, please let me know.
GhostDriver is a Selenium server that can be connected to via a RemoteWebDriver.
It runs completely heedlessly on PhantomJS but still behaves (mostly) like a typical webkit browser. By avoiding the overhead of actually rendering the page in a GUI it can run standard Selenium tests noticeably faster and on a headless build server too.
This is especially beneficial if you want to use continuous testing IDE plugins like Infinitest or JUnitMax or simply to encourage developers to run end-to-end tests more frequently.
GhostDriver is written on top of PhantomJS, a headless WebKit browser which uses QtWebKit.
It’s already 35%-50% faster than ChromeDriver despite the fact that QtWebKit has the standard WebKit Javascript engine. QtWebKit is moving to the V8 JS engine (as used in Chrome) which means it’s only going to get faster…
It’s still work in progress and hasn’t implemented the entire Selenium wire protocol yet but it’s certainly one to watch.
In a previous article, This is not a manifesto, I expressed the values I hold as a software development team member. Today, I’m going to talk about the first of these values.
Before I do, I’d like to say what I mean by “software development team”. I mean a cross-discipline team with the combined skills to deliver a software product – product owner, user experience, business analysts, programmers, testers, dev-ops, etc.
A common problem
Many teams I encounter will, at least in the beginning, have team-members who specialise in a single role. Each team-member will rarely, if ever, step outside their job description [1]. This can cause a problem.
Many teams find themselves in a situation where some team members have little to do on the current stories. At this point, the team has some choices, they can focus the under-utilised people on:
Future user-stories, working on tasks most relevant to their job title
Another team, working on tasks most relevant to their job title (e.g. ‘matrix management’)
Current stories, taking on tasks that will take the story to completion sooner, even if it’s more relevant to someone else’s job title
Things that will make the more utilised people get through their work faster, today and in the future.
More often than not, I find teams taking option 1. I think that people choose this option because it feels like it should increase the throughput of the team – i.e. the amount of new features they can add to the product. In fact, it has the opposite effect.
Little’s law
Let’s consider a team that is working in time-boxes or ‘sprints’ (à la Scrum) and measures it’s throughput with ‘velocity’ (story-points per-sprint). Points are accrued as each user-story is completed – i.e. coded, tested and product-owner validated.
In this particular team, it is able to complete an average of 10 points per sprint. Let’s say this is due to a bottleneck in the process. This bottleneck might limit the amount of testing that can be completed during the sprint. This is illustrated in fig.1 where each ball is a story point.
Little’s law [2] tells us that the amount of time it takes to complete an item of work (cycle-time) is:
Work in Progress (WIP) Throughput
Which we can read as:
story points in progress velocity
In this simplified example, WIP is 10 points and throughput is 10 points per sprint. The average cycle time of a story is therefore 10/10 = 1 sprint. Notice, however, there’s all that spare capacity.
Let’s say this spare capacity is developers. So, the team starts taking on more user-stories from the backlog – increasing the number of story points in progress to 20 points (fig.2).
Because the bottleneck remains, velocity remains the same – 10 points per sprint. The amount of flexibility that the team has, however, is now reduced because the average time required to get a story to completion has increased from 1 sprint to 20/10 = 2 sprints [3].
Often this will take the form of testers working a sprint behind the developers. Worse still, over 10 sprints, the team still only completes 100 story points (as they would have before) but is left with a lot of unfinished work. This ‘inventory’ of unfinished work carries overheads which can, ultimately, reduce the velocity of the team.
The impact of filling capacity in this way has yet another effect.
Latency effect
As the developers get through more stories, a queue of stories that are “ready for testing” will build up. Testers working through these will, at least, have questions for the developer(s) or even find some defects. The developer, having moved on from that story, is now deep into the code and context of another story. When the tester has questions, or finds defects, relating to a story that the developer had worked on, say a week ago, then the developer has to reload their understanding of this old code and context in order to answer any questions or fix any defects. This context-switching carries significant overheads [4].
The end result is that the effort required to complete a story increases due to the repeated context switching, therefore reducing velocity.
So, not only does filling the capacity with more work fail to increase throughput, it adds costly context-switching overheads – ultimately slowing everything down.
This phenomenon is not unique to teams using fixed-length time-boxes, such as sprints. Strictly following Kanban avoids this problem, but what I’ve seen is some teams creating a ‘ready for testing’ queue – so that developers can start work on the next story. This has the same latency effect and turns a process designed for continuous flow into a batch and queue process. But, I digress.
What to do with the spare capacity?
The simple answer is to look at the whole approach and determine what is slowing things down. In the example above, I’d be wondering what’s slowing the testing down. Many of the things that hinder testing can be addressed by changing how we do things ‘upstream’.
Are lots of defects being found, causing the testers to spend more time investigating and reproducing them? Can we get the testers involved earlier? Can any predictable tests be defined up front so that developers can make sure the code passes them before it even gets to the testers (e.g. Behaviour Driven Development)?
Are the testers manually regression testing every sprint? Could the developers help by automating more of that? Are the testers having to perform repetitive tasks to get to the part of the user-journey they’re actually testing? Can that be automated by the developers?
Is there anything else that is impacting them? Test data set-up and maintenance, product owner availability to answer questions? Anything else?
Addressing any of these issues is likely to speed up the testing process and increase throughput of the entire team as a result. One solution is to put these types of tasks onto the product backlog. This is fine but if we assign point values to them it can give a skewed view of velocity. Or rather, velocity is no longer a measure of throughput. You won’t be able to see if these types of tasks are actually improving things unless you are also measuring what proportion of the points are delivering new product capabilities.
The only good reason I can think of for story-pointing these throughput-enhancing tasks is if your focus is utilisation – i.e. maximising the number of story-points in progress. Personally, I care more about measuring and improving throughput. By doing so, we get the right utilisation for free and a faster, more capable team.
Up next:Valuing Effectiveness over Efficiency.
Footnotes:
[1] “Lessons Learned in Close Quarters Battle” Illustrates how stepping outside our job descriptions can move the team through each story more quickly by using special-forces room-clearing as an analogy.
[2] Little’s law (PDF) – the section “Evolution of Little’s Law in Operations Management” that references Hopp and Spearman’s observation about throughput (TH), work-in-progress (WIP) and cycle-time (CT) – i.e. TH=CT/WIP. And therefore we can say CT = WIP/TH.
[3] Little’s law also illustrates that if we reduce the work in progress to one quarter, then the cycle time for each story reduces to one quarter of a sprint. We’ll still get through 10 points per sprint, but stories will be completed more as a continuous stream throughout the sprint rather than all at the end.
[4] “The Multi-Tasking Myth” by Jeff Atwood, talks about multi-tasking across projects and pulls together several resources to illustrate the impact of multitasking at various levels. This applies when multi-tasking across stories.
Acknowledgements:
I’d like to say a special thank you to my fellow RiverGliders – Andy Palmer and James Martin – for the feedback that helped me refine this article.
Acceptance Criteria, Scenarios, Acceptance Tests are, in my experience, often a source of confusion.
Such confusion results in questions like the one asked of Rachel Davies recently, i.e. “When to write story tests” (sometimes also known as “Acceptance Tests” or in BDD parlance “Scenarios”).
In her answer, Rachel highlighted that:
“…acceptance criteria and example scenarios are a bit like the chicken and the egg – it’s not always clear which comes first so iterate!”
“where she explains that acceptance criteria are general rules covering system behaviour from which executable examples (Scenarios) can be derived“
Seeing the acceptance criteria as rules and the scenarios as something else, is one way of looking at it. There’s another way too…
Instead of Acceptance Criteria that are rules and Acceptance Tests that are scenarios… I often find it useful to arrive at Acceptance Criteria that are scenarios, of which the Acceptance Tests are just a more detailed expression.
I.e. Scenario-Oriented Acceptance Criteria.
Expressing the Intent of the Story
Many teams I encounter, especially newer ones, place higher importance on the things we label “acceptance criteria” than on the things we label “acceptance tests” or “scenarios”.
By this I mean that, such a team might ultimately determine whether the intent of the story was fulfilled by evaluating the product against these rules-oriented criteria. Worse still, I’ve observed some teams also have:
Overheads of checking that these rule-based criteria are fulfilled as well as the scenario-oriented acceptance tests
Teams working in silos where BAs take sole responsibility of criteria and testers take sole responsibility for scenarios
A desire to have traceability from the acceptance tests back to the acceptance criteria
Rules expressed as rules in two places – the criteria and the code
Criteria treated as the specification, rather than using specification by example
If we take the approach of not distinguishing between acceptance criteria and acceptance tests (i.e. see the acceptance tests as the acceptance criteria) then we can encourage teams away from these kinds of problems.
I’m not saying it solves the problem – it’s just easier, in my experience, to move the team towards collaboratively arriving at a shared understanding of the intent of the story this way.
To do this, we need to iteratively evolve our acceptance criteria from rules-oriented to scenario-oriented criteria.
Acceptance Criteria: from rules-oriented to scenario-oriented:
Let’s say we had this user story:
As a snapshot photographer
I want some photo albums to be private
So that I have a backup of my personal photos online
And let’s say the product owner first expresses the Acceptance Criteria as rules:
Must have a way to set the privacy of photo albums
Private albums must be visible to me
Private albums must not be visible to others
We might discuss those to identify scenarios (as vertical slices through the above criteria):
Create new private album
Make public album private
Make private album public
Here, many teams would retain both acceptance criteria and scenarios. That’s ok but I’d only do that if we collectively understood that the information from these two will come together in the acceptance tests… And that whatever we agree in those acceptance tests supersede the previously discussed criteria.
This understanding tends to occur in highly collaborative teams. In newer teams, where disciplines (Business Analysts, Testers, Developers) are working more independently this tends to be harder to achieve.
In those situations (and often even in highly collaborative teams) I’d continue the discussion to iterate over the rules-oriented criteria to arrive at scenario-oriented criteria, carrying over any information captured in the rules, discarding the original rules-based criteria as we go. This might leave me with the following scenarios:
Create new private album (visible to me, not to others)
Make public album private (visible to me, not to others)
Make private album public (visible to me, & others)
Which, with a subtle change to the wording, become the acceptance criteria. I.e. the story is complete when we:
Can create new private album (visible to me, not to others)
Can make public album private (visible to me, not to others)
Can make private album public (visible to me, & others)
Once the story is ‘in-play’ (e.g. during a time-box/iteration/sprint) I’d elaborate these one at a time, implementing just enough to get each one passing as I go. By doing this we might arrive at:
Scenario: Can Create new private album
When I create a new private album called "Weekend in Brighton"
Then I should be able to see the album
And others should not be able to see it
Scenario: Can Make public album private
Given there is a public album called "Friday Night"
When I make that album private
Then I should be able to see the album
And others should not be able to see it
Scenario: Can Make private album public
Given there is a private album called "Friday Night"
When I make that album public
Then I should be able to see the album
And others should be able to see it
By being an elaboration of the scenario-oriented acceptance criteria there’s no implied need to also check the implementation against the original ‘rules-oriented’ criteria.
Agreeing that this is how we’ll work, it encourages more collaborative working – at least between the Business Analysts and Testers.
These new scenario-based criteria become the only means of determining whether the intent of the story has been fulfilled, avoiding much of the confusion that can occur when we have rules-oriented acceptance criteria as well as separate acceptance test scenarios.
In short, more often than not, I find these things much easier when the criteria and the scenarios are essentially one and the same.
Let’s say you own a restaurant. Quite a large restaurant. You’ve hired a manager to run the place for you because you are about to take the fruits of your success and invest in opening three more around the country. You leave the manager with a budget to make any improvements he sees fit.
After being away for a few weeks, you return to your restaurant. It’s very busy thanks to the great reputation you had built for it. The kitchen has some new state of the art equipment and you can see that there are a lot of chefs and kitchen-staff preparing meals furiously. Obviously, with a restaurant this full you have to prepare a lot of meals.
Too many chefs?
But then, you notice that there are only a few service staff taking orders and delivering the meals to the customers. Tables are waiting a long time for their meals. You notice the service staff spending a lot of their time taking meals back to the kitchen because they have gone cold waiting so long to be served. You also overhear several customers complaining that the meal they received was not the one they ordered, increasing the demand for the preparation of more meals. You call the manager over and ask him what’s going on… he says “because we need to invest more in the kitchen”. You wonder why. He tells you “because there are so many meals to prepare and we can’t keep up”.
At this point, it’s quite obvious that the constraint is not through lack of investment in the kitchen. Instead the lack of investment is in taking the right orders and getting the meals to the customers. To solve this, I think most people would increase the investment in getting the order right and in how the meals get to the customer not by investing more into the kitchen.
Obvious, right? Despite this, time and again, I see organisations happy to grow their investment in more programmers writing more code and fixing more bugs and all but ignore the end-to-end process of finding out what people want and taking these needs through to working capabilities available to the customer. Business analysis, user-experience, testing and operations all seem to suffer in under investment. If it takes you four weeks to write some code for several new features and then another four weeks for that to become capabilities available to your customer, hiring more programmers to write more code is not going to make things any better.
Sushi and Hibachi
So, how would you advise the restaurant? In the short term, you can get some of the chefs to serve customers while you hire more service staff. Another solution is to invest in infrastructure that brings the meals closer to the customer, such as in hibachi restaurants where the chef takes the order and cooks the meal at the table or in sushi restaurants where meals are automatically transported via conveyor belt.
In software teams, we can bring the preparation of features closer to our customers. We can involve a cross-functional team in the conversation with the customer (such as the chef being at the customer’s table). We can also automate a large proportion of the manual effort of getting features from a programmer’s terminal into the hands of the customer (as in with the conveyor belt). And, there is so much we can automate.
Integration, scripted test execution, deployment and release management can largely be automated. Since speeding up these tasks has the potential to increase the throughput of an entire development organisation, it seems appropriate to invest in these activities as we would in automating any other significant business activity – such as stock-control or invoice processing.
Cooking for ourselves
Why not ask a good number of our programmers to take some time out from automating the rest of the business and automate more of our own part of the business? Taking this approach seems to be the exception rather than the rule. I see organisations having one or two dev-ops folks trying to create automated builds; and similar number of testers, with next to no programming experience, trying to automate a key part of the business – regression testing. And then asking them all to keep up with an army of developers churning out new code and testers churning out more scripted tests.
Serving up the capabilities
Instead, let’s stop looking so closely at one part of the process and look more at the whole system of getting from concept to capability. Let’s invest in automating for ourselves as much as we automate for others – and let’s dedicate some of our best people to doing so.
In short, it’s not just about the speed at which we cook up new features. It’s as much about the speed at which we can serve new, working capabilities to our customers.
Elop drew out what he knew about the plans for MeeGo on a whiteboard, with a different color marker for the products being developed, their target date for introduction, and the current levels of bugs in each product. Soon the whiteboard was filled with color, and the news was not good: At its current pace, Nokia was on track to introduce only three MeeGo-driven models before 2014-far too slow to keep the company in the game.
This brought to mind some blog posts I wrote in early 2010 (now copied to this blog – see previous two entries). I talked about ‘critical mass’…
Critical Mass of Software: the state of a software system when the cost of changing it (enhancement or correcting defects) is less economical than re-writing it.
In the case of Nokia and MeeGo, there isn’t enough information to know if that’s what had happened but it does suggest, at least, that it was more economical to choose an alternative third-party OS than to continue with MeeGo. Integrating Windows Mobile is going to come at some cost, of course, but clearly they decided it was less than sticking with their current strategy.
This is an example of modern markets demanding more sustainable, adaptive and agile product development cycles, and a company recognising this and acting on it.
It is also a demonstration of how an ever-growing cost of change (e.g. through the number of bugs consuming resources that would otherwise be adding new value) is really deferring of cost – i.e. technical debt.
There are many arguments for ‘prudent’ acceptance of technical debt… This story, I think, is an example of where it wasn’t obvious when that debt was no longer prudent until it was too late for MeeGo as a product.
And this is one of the problems with some lean concepts applied to new products and start-ups. The advice is often to get feedback from the market quickly by hacking the product together and release as quickly as possible. The trouble is, at what point do we take a step back and change to more sustainable practices? Probably around the time the product is selling… but then we’re under pressure from competitors who have seen our innovations and want to copy them… so we’re tempted to keep hacking out more features only to find that the faster we hack the slower we go.
There is no magic answer, to the question “when do we stop hacking and start sustainably building?” We might wait until we’re making enough money to hire more people to do remedial work.
As soon as we find we’re enhancing a feature, it might mean that it’s a key part of our product – one we’re going to keep. We might then treat any code we touch during that enhancement as legacy code, building in the cost of remedial work into the enhancement.
Some would argue that it’s faster overall to never hack things in and to commit to sustainable product development practices from the get-go. This probably applies in many cases but especially to large complex products like operating systems.
Whatever the strategy used, there will come a point where you can’t hack in any more features. The question is, will you decide when that happens or will the cost of change decide for you.
In a previous post I talked about Critical Mass of software. I showed how an ever-increasing cost of change resulted in it becoming more economical to completely rewrite the system than to enhance and maintain the original.
I explained how this could be avoided by using practices that sustain a consistent and flat cost of change. I also mentioned that you could defer reaching critical mass. Some teams find it difficult to get the time to do this because “the business” always has “more important” or “higher-value” things on their backlog.
What are the implications of reaching critical mass? Well, depending on what the software does and whether the rewritten version still has to do all of those things, it could cost millions… or more.
Presented with the situation that the product could reach critical mass within a year – costing millions to replace – do you think “the business” would start to think it is worth investing in reducing the cost of change? Obviously, I would advise teams to avoid this situation in the first place:
The reality for many teams I’ve encountered is that they don’t feel empowered to push back on the business’ demands for that next feature in half the time it takes to do it properly. If we could present back the impact of that choice as shortening the time to Critical Mass and bringing about costs to replace the software far in excess of the value gained by delivering that feature a month early then perhaps the business would be better informed.
A big visible chart on the wall, showing the estimated point at which Critical Mass was reached could play a big role in getting the business more interested in sustainable change, or at least inspire a conversation on the subject.
Convincing “the business” to invest in some remedial refactoring or allowing three times as long for each feature to facilitate enough remedial refactoring for each new feature and refactoring-as-we-go for the new feature might be easier if we could represent this idea visually:
The problem with this idea is how do we credibly determine when Critical Mass is going to be reached? Many experienced practitioners could probably reasonably accurately estimate when that was going to happen purely on gut feel but this would be torn to pieces by many product managers. I’ve not solved this problem yet because doing this would require a mathematical model, determined by empirical data.
Perhaps someone will take inspiration from the ideas in these blog posts and find a solution. Perhaps someone has already done this or maybe this is an idea for a future PhD I might undertake? Maybe someone else will take inspiration from this article and undertake that work before I do. If so, they’re welcome to (with due attribution where applicable of course 😉
I think it is possible, however, to come up with a simple model based on the average complexity per unit of value (assuming that the team is using value and complexity). Trending this and keeping an estimate of a complete re-write up to date might allow the simple charts above to be maintained along side release-level burn-down charts.
These ideas are still in their infancy for me. Has this problem been solved already? If not, I encourage others to explore my hypothesis and help take it from just an interesting idea to something more useful.
Critical Mass of Code – past which the changeability of the code is infeasible, requiring that it be completely rewritten.
An elaboration of this might be:
Critical Mass of Software: the state of a software system when the cost of changing it (enhancement or correcting defects) is less economical than re-writing it.
This graph illustrates a hypothetical project where the cost of change increases over time (the shape of which reminds me of a thresher shark):
Note:The cost of a rewrite gradually grows at first to account for the delay between starting the re-write and achieving the same amount of functionality in the original version of the software at the same point in time. The gap between the cost-of-change and the cost-of-rewrite begins to decrease as the time it takes to implement each feature of comparable benefit in the original version grows.
One opportunity that I feel organisations miss out on is that this can be used as a financial justification for repaying technical debt, thus preventing or delaying the point at which software reaches its Critical Mass, or avoiding it altogether.
Maintaining quality combined with practices that keep the effort involved in completing each feature from growing over time can defer critical mass indefinitely:
Note: The cost of a rewrite is slightly less at first assuming that we are doing a little extra work to ensure that we get the infrastructure we need up and running to support sustainable change (e.g. continuous integration etc.)
This flat cost of change curve is one of the motivations of many agile practices and software craftsmanship techniques, such as continuous integration, test-driven-development, behaviour driven development and the continuous refactoring inherent in the latter two. A flat cost-of-change trend is good for the business, as they have more predictable expenditure.
The behaviour I’ve noticed with some teams is to knowingly accrue technical debt to shorten time to a near-future delivery in order to capitalise on an opportunity and then pay it back soon after:
This certainly defers reaching critical mass but it doesn’t prevent it.
Unfortunately, I see more teams taking on technical debt and not repaying it (for various reasons, often blamed on “the business” putting pressure on delivery dates).
If we had a way of estimating the point at which we’d reach critical mass, we’d be able to compare the benefit of repaying technical debt now in order to avoid or delay the cost of a rewrite… or even better, demonstrate the value of achieving a flatter cost of change.
I’m not sure that we have the data or the means of predicting it, but perhaps these illustrations of a hypothetical scenario will help you explain why sustaining constant quality, automating repeatable tests (or checking as some prefer to call it) wherever technically possible and, on those occasions when we do need to make a conscious choice to compromise quality to capitalise on an opportunity, that the debt is repaid soon after.
One company I know reached this point a couple of years ago and embarked on a department wide transformation to grow their skills in agile methods so that they not only re-wrote the software but could also avoid ever reaching critical mass again. A bold move, but one that paid off within a year. Even for them, they’ll need to avoid complacency as time goes on and not forget the lessons of the past. Let’s hope they do.
“Few would think that Special Forces tactics bear any relation to software project teams. But Antony Marcano draws a surprising parallel between the dynamics of modern Special Forces “room-clearing” methods and the dynamics of modern software development teams.”
My thinking has moved on slightly since then. Recently, several people have expressed an interest in the article.
So, here is an updated version, based on my more recent thinking and with some additional detail that had to be omitted from the original due to word-count restrictions of publishing in printed form…
Please note – The comparison with military and police armed forces is purely metaphorical and specific to the message I hope emerges about roles and titles.
Lessons Learned in Close Quarters Battle
I’m at the door, heart pounding so loud I’m sure everyone can hear it. Four silhouettes are flat to the wall. I’m point man, stuck to the edge of the door we’re about to breach. The team lead whispers through a covert radio mike, “Alpha 1 in position.” Silence… tense anticipation… then, after a thirty-second eternity, my earpiece crackles as control responds, “Standby… Standby… Strike! Strike! Strike!”
The method of entry (MOE) man, on the opposite edge of the door frame, kicks in the door; behind me, the team lead throws in a stun grenade. BANG! As point man, I enter immediately—followed by number two—and five action-packed seconds and three targets later, we’re able to call out “ROOM CLEAR!”
Instantly, we move to the next room. The MOE man is nearest to it, immediately becomes point-man. The man on rear cover follows taking up the MOE position, becoming the MOE man. Meanwhile, the original number two and I are exiting the room.
I’m the first out and, seeing that the number two position on the next door is yet to be filled, I fall in behind the point man, becoming team lead. I am now responsible for calling the next breach and for throwing in the next flash-bang. The former number-two drops in behind me to provide rear cover. Each of us instantly switches roles, and with a deafening bang, the next door is breached without hesitation.
This might sound like a scene from an action movie but, no, it was a close quarters battle (CQB) training session I attended with the rest of The Foundation:Special Operations Group—a top UK Airsoft team. Airsoft is a skirmishing sport similar to paintball but with more realistic looking equipment and no mess.
In this training session, run by a private security contractor, we were practicing the latest CQB techniques taught to police and military armed forces. In CQB situations, armed forces don’t have time to shuffle around to get team members into the position that an individual’s job title might dictate. Lives are at stake (or points in Airsoft). The team must be able to adapt instantly; there can be no waste in the process.
Fixed Roles are accompanied by Waste
Historically, CQB dynamic entry (room clearing) was, and still is in places, taught with fixed roles. Instead of each person reading the situation and falling into the position that maximises the flow of the team from room to room, each person had a fixed role.
Prior to practicing the dynamic role-switching, or ‘read system’ we also tried the fixed role position. This was noticeably slower. Instead of the team-members outside the room falling straight into the position on the next room, they had to wait for the number 1 & 2 (and sometimes number 3) to exit the first room and get into position covering the next door. Only then could the MOE specialist move to the door allowing the last team-member to move up to continue their role providing rear cover.
The extra time it takes waiting for each specialist to be in position can take 10-30 seconds longer per-room. This time adds up to several minutes of wasted time when you have a whole series of rooms to clear. This fixed-role system not only puts the same person at the greatest risk as point-man on each room, as was highlighted by a British Army CQB instructor I trained with last year, but reduces your flexibility or can even halt the operation—especially when one of your team-members is injured (or worse).
If everyone is a specialist, you need more people in those specialist roles to deal with the risk that one of them could be taken out at any time. We don’t have quite this concern in software teams, however, people do fall ill or need time off work for personal reasons.
We Still Need Experts
Indeed, there are experts within a dynamic team. For example, our MOE expert might tackle the especially tricky entries or advise the team on entry tactics before the game, but we all are capable to some degree in MOE. Each of us is capable of dynamically switching roles, quickly adapting to changing circumstances. This is a perfect example of a truly cross-functional team of generalising specialists [1].
Skills Demands are Constantly Changing
This dynamic role switching is almost the opposite of your typical software organisation where each person has a job title that fixes his role—business analyst, programmer, tester. These job titles make complete sense in phased-development approaches (e.g. waterfall) where the work is divided up as if it were a production line: Business analysts pass the outcome of business analysis to developers who pass the result of development on to testers and so on. These job titles make less sense when using agile approaches that integrate these activities so tightly that they are all but inseparable.
More significantly, however, the balance of skills needed during each iteration (or time-box) and even for each user-story fluctuates depending on the nature of the features being implemented. One change may involve more refactoring (changing internal and not external behaviour) and be largely protected by pre-existing automated tests. Another change may involve limited coding and much more exploratory testing. There are endless variations on how the emphasis on each skill-area will change as the work flows through our value-stream.
Like the Airsoft (or Special Forces) team going from one room to the next, software teams must seamlessly go from one story (or feature or business-value-increment) to the next. It’s simply too wasteful for progress to be halted while we wait for a fixed-role specialist to finish his previous task.
Everyone on the team must constantly adapt so that we continue to maintain a constant and efficient flow of value… Fulfilling our shared responsibility of frequently delivering working software.
History Repeating?
An increasing number of organisations seem to recognize this, creating a demand for multi-skilled people. Interestingly, however, history seems to be repeating itself!
Up to the mid 1990s, high- and low-level software design was performed by systems analysts and then coded by programmers. Perhaps due to the demands of rapid application development, the roles later combined and the multi-skilled analyst-programmer emerged. Subsequently, this became the norm and analyst-programmers were thereafter known only as “developers.”
Today the title of developer-tester (or tester-developer) is emerging in response to the flexibility demanded by agile teams—kind of an analyst-programmer-tester. As the uptake of agile methods grows, this demand is only going to rise! If history indeed repeats itself, the developer-tester may, too, become the norm—negating the need for the “tester” suffix that differentiates them. Yes, the “software tester” job title, one of the few remaining titles derived from phased-development methods of old, could suffer the same fate as Ye Olde Systems Analyst.
This wouldn’t mean that software testing as a discipline will disappear altogether—just that many of the testers and developers of today will need to leave their comfort zones to become the developers of tomorrow.
Acquire ‘Tags’ or Badges – not a Job Title
Fixed, specialised job titles alone could be part of the problem. Maybe we need to stop linking specific roles to job titles. So often at conferences people ask the audience, “put your hand up if you are… analysts… programmers… testers… designers…”
I notice that many people will only put their hand up when one of these is called. You may notice me put my hand up for each of these roles. I think of these labels more like tags than titles. I feel I can tag myself with all of these roles and switch between them (to varying degrees of competency) as the situation demands.
Maybe they’re not so much like tags as badges. In some forces and certainly in the cadets and even among scouts and brownies, as you demonstrate new skills, you are entitled to wear new badges.
The difficulty with fixed-role thinking is that for many, their very identity is attached to their job titles. The challenge becomes showing people why they would want to broaden their thinking. I’m not sure I have time to address that in this particular post.
Maximise (your) Value
I can tell you what’s in it for me, personally. The tasks most relevant to my job-title may not be relevant to the team’s current story or goals. By dynamically switching roles, I am able to do the task that is the most relevant and valuable to the team at that time, within the context of the project’s goals, rather than just the tasks of most relevance to my job title. I am then able to accelerate the speed at which the team can clear each story, as the CQB team clears each room.
I recognise that this isn’t always immediately practical. Some teams are very protective over access to source code… but this is a matter of trust. There are many ways you can earn this trust… It may be that you need to demonstrate your abilities to manage your own git, mercurial or subversion repository before you’ll be given access to the relevant project repositories. It may be that you can demonstrate that you are able to build an open-source code-base using similar technology on your own. You may simply need to be able to talk about the right things while asking another team-member with a different area of expertise for help – demonstrating that you’ve at least understood the basics. So, one of the things outside your job-title that may add value to the team might be learning how to do something that the team will soon need doing.
So, hold on to your job titles and stick to your job descriptions if you choose. Personally, I’ve chosen to develop my individuality, embrace new skills and acquire new ‘tags’ & badges—bringing to the team more value, flexibility, throughput and opportunity.
References: [1] Ambler, Scott. “Generalizing Specialists: Improving Your IT Career Skills.” Agile Modeling, 2006. www.agilemodeling.com/essays/generalizingSpecialists.htm
To find out more about Airsoft or to take your colleagues on a similar journey to this article, check out http://firefight.co.uk. Tell them that this article sent you their way… they know who I am and have already taken one of my client’s teams on a similar journey.
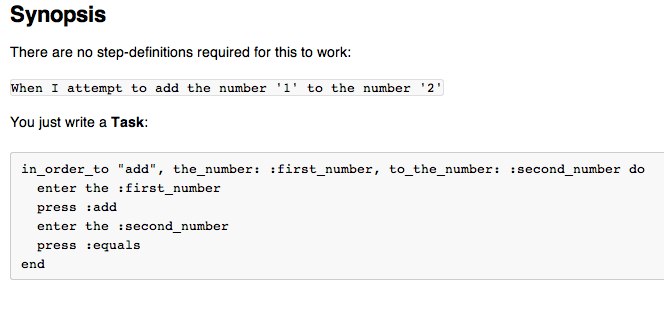
Goal: What we’re trying to achieve which has one or more… Tasks: The high-level work-item that we complete to fulfil the goal, each having one or more… Actions: The specific steps or interactions we execute to complete the task.
I showed how many scenarios (acceptance tests) are pitched at too low a level. They’re often at the action level, detailing every field filled in and every button clicked. This is too low-level.
Instead, we want to express the business process… the tasks involved in fulfilling a goal. The actions should be expressed in the code (or step-definitions), not the plain-text scenarios. Pitching the scenarios at the action level makes scenarios much harder to maintain – especially when the user-interface changes. But, perhaps more importantly, they don’t express what’s of interest to the business.
Coverage vs. Speed tradeoffs of running scenarios through or below the GUI (respectively)
We’ve taken many of the lessons we’ve learned using BDD tools to address these problems and begun to distill the various heuristics and design ideas (patterns) that emerged into a single open-source extension to cucumber – cukesalad.
Many of the heuristics and design ideas expressed in the project can be used on your existing projects without using cukesalad:
Treat each step-definition as a class of task. Like other classes, have one file per step-definition and organise them so they’re easy to find. Name each file using the text used in the scenario.
Abstract the API that drives your application behind something representing the role or type of role involved in the story
Write scenarios like a narrative for someone in the role relevant to the user-story
Write the actions within the task (or step-definition) as if they’re instructions on how to complete that task
And more…
Cukesalad is the ongoing expression of us mercilessly refactoring a ‘typical’ Cucumber project. At the moment, it is more of an illustration of the concepts and ideas… but some are already using it on their day-to-day projects. Check it out… try it out… and let us know what you think.