Gearboxes in competitive motor racing are designed to shift as fast as possible. A competitive race-car has computer controlled, hydraulically activated gear shifts that change gears up or down faster than you can blink (literally)! In Formula One, each shift is so fast that the gearbox systems have been dubbed “seamless shift” gearboxes and can shift gear in around 2-4 100ths (0.02 – 0.04) of a second. Compare that to the circa 1-2 second gear-shift a competent driver takes to manually de-clutch, change gear and re-clutch on a road car. Even automatic gearboxes on road cars can’t keep pace with the rapid gear changes that a race car delivers.
Competitive Edge
The race car is only saving fractions of a second with each accelerated up-shift, but the race-driver changes gear so often per lap and there are so many laps in a race that these fractions of a second can add up to a vital and significant lead over their competitors.[1]
Set aside the lap-time improvements for a moment from spending at least half a second more on the power per up-shift than with a manual box… The modern F1 driver has much more to do in the cockpit too than the comparative tedium of changing gear [2].
Developer race-tech
Now, in motor racing, such gearboxes are taken for granted. No serious Formula One racing team would put their car on the track without one.
In a world where a lot of software development is for companies competing in the economical equivalent of a race, it seems that development teams aren’t taking full advantage of their own metaphorical millisecond gear-shifts.
There are tools that are a developer’s equivalent of a racing gearbox. The simplest example is background compilation. Other examples are refactoring tools that make widespread changes with a simple key-stroke. What once took minutes or hours with global find & replace or even scripting, we can complete in seconds. IDEs that automatically complete class-names and method names are another example. These are tools that many of us take for granted, like the racing driver and automated gear-shift.
Falling behind
But there are other places where we are still not taking full advantage of the technology. I am still encountering surprisingly few people using continuous testing tools, where tests are run automatically in the background every time a file is saved, and not just the test I’m working on, all my tests. There are a few tools available for this, including Infinitest and ZenTest.
Despite the availability of such tools, I still see many developers using keyboard shortcuts to execute tests. Or, worse, reaching for the mouse, right-clicking, navigating another menu level down and running the tests with a left-click, or worse still, forgetting to run them altogether. I want rapid feedback with minimum friction to obtaining it. Much like background compilation, unit tests should just run, and run often, alerting us when a problem occurs. The easier they are to run, the more likely we are to run them… How much easier could it be than it happening automagically each time we save a file?
Need for Speed
Try it for a while and, like me, even keyboard-shortcut executed tests start to feel like you’re stuck in traffic rather than being in a competitive race to the finish… Or, maybe it’s just me and my need for speed…
The video is of me on the Silverstone Southern Circuit (part of the F1 GP circuit) taking my UK National Class B Racing License Test in a Nissan R35 GTR – approx 480+bhp, 0-62mph (0-100kmh) in 3.5secs, using it’s double-clutch, paddle-operated gear-shift providing gear changes in about 0.2 of a second. I passed… despite being very cautious on the brakes… and was noticeably quicker than the other person doing their test… which you see towards the end as I pass them 🙂
[1] At the Monaco GP, an F1 driver will change gear around 50-60 times in one lap. Over 78 laps, this adds up to as many as 4680 gear changes over the whole race (up and down-shifts).
[2] The comparative tedium of de-clutching, shifting and re-engaging the clutch is something that a race-driver should not need to worry about as they approach 200mph while adjusting the brake-balance lever, switching to a new fuel-air mixture setting, pressing the KERS boost button and/or deactivating the Drag Reduction System.
“Few would think that Special Forces tactics bear any relation to software project teams. But Antony Marcano draws a surprising parallel between the dynamics of modern Special Forces “room-clearing” methods and the dynamics of modern software development teams.”
My thinking has moved on slightly since then. Recently, several people have expressed an interest in the article.
So, here is an updated version, based on my more recent thinking and with some additional detail that had to be omitted from the original due to word-count restrictions of publishing in printed form…
Please note – The comparison with military and police armed forces is purely metaphorical and specific to the message I hope emerges about roles and titles.
Lessons Learned in Close Quarters Battle
I’m at the door, heart pounding so loud I’m sure everyone can hear it. Four silhouettes are flat to the wall. I’m point man, stuck to the edge of the door we’re about to breach. The team lead whispers through a covert radio mike, “Alpha 1 in position.” Silence… tense anticipation… then, after a thirty-second eternity, my earpiece crackles as control responds, “Standby… Standby… Strike! Strike! Strike!”
The method of entry (MOE) man, on the opposite edge of the door frame, kicks in the door; behind me, the team lead throws in a stun grenade. BANG! As point man, I enter immediately—followed by number two—and five action-packed seconds and three targets later, we’re able to call out “ROOM CLEAR!”
Instantly, we move to the next room. The MOE man is nearest to it, immediately becomes point-man. The man on rear cover follows taking up the MOE position, becoming the MOE man. Meanwhile, the original number two and I are exiting the room.
I’m the first out and, seeing that the number two position on the next door is yet to be filled, I fall in behind the point man, becoming team lead. I am now responsible for calling the next breach and for throwing in the next flash-bang. The former number-two drops in behind me to provide rear cover. Each of us instantly switches roles, and with a deafening bang, the next door is breached without hesitation.
This might sound like a scene from an action movie but, no, it was a close quarters battle (CQB) training session I attended with the rest of The Foundation:Special Operations Group—a top UK Airsoft team. Airsoft is a skirmishing sport similar to paintball but with more realistic looking equipment and no mess.
In this training session, run by a private security contractor, we were practicing the latest CQB techniques taught to police and military armed forces. In CQB situations, armed forces don’t have time to shuffle around to get team members into the position that an individual’s job title might dictate. Lives are at stake (or points in Airsoft). The team must be able to adapt instantly; there can be no waste in the process.
Fixed Roles are accompanied by Waste
Historically, CQB dynamic entry (room clearing) was, and still is in places, taught with fixed roles. Instead of each person reading the situation and falling into the position that maximises the flow of the team from room to room, each person had a fixed role.
Prior to practicing the dynamic role-switching, or ‘read system’ we also tried the fixed role position. This was noticeably slower. Instead of the team-members outside the room falling straight into the position on the next room, they had to wait for the number 1 & 2 (and sometimes number 3) to exit the first room and get into position covering the next door. Only then could the MOE specialist move to the door allowing the last team-member to move up to continue their role providing rear cover.
The extra time it takes waiting for each specialist to be in position can take 10-30 seconds longer per-room. This time adds up to several minutes of wasted time when you have a whole series of rooms to clear. This fixed-role system not only puts the same person at the greatest risk as point-man on each room, as was highlighted by a British Army CQB instructor I trained with last year, but reduces your flexibility or can even halt the operation—especially when one of your team-members is injured (or worse).
If everyone is a specialist, you need more people in those specialist roles to deal with the risk that one of them could be taken out at any time. We don’t have quite this concern in software teams, however, people do fall ill or need time off work for personal reasons.
We Still Need Experts
Indeed, there are experts within a dynamic team. For example, our MOE expert might tackle the especially tricky entries or advise the team on entry tactics before the game, but we all are capable to some degree in MOE. Each of us is capable of dynamically switching roles, quickly adapting to changing circumstances. This is a perfect example of a truly cross-functional team of generalising specialists [1].
Skills Demands are Constantly Changing
This dynamic role switching is almost the opposite of your typical software organisation where each person has a job title that fixes his role—business analyst, programmer, tester. These job titles make complete sense in phased-development approaches (e.g. waterfall) where the work is divided up as if it were a production line: Business analysts pass the outcome of business analysis to developers who pass the result of development on to testers and so on. These job titles make less sense when using agile approaches that integrate these activities so tightly that they are all but inseparable.
More significantly, however, the balance of skills needed during each iteration (or time-box) and even for each user-story fluctuates depending on the nature of the features being implemented. One change may involve more refactoring (changing internal and not external behaviour) and be largely protected by pre-existing automated tests. Another change may involve limited coding and much more exploratory testing. There are endless variations on how the emphasis on each skill-area will change as the work flows through our value-stream.
Like the Airsoft (or Special Forces) team going from one room to the next, software teams must seamlessly go from one story (or feature or business-value-increment) to the next. It’s simply too wasteful for progress to be halted while we wait for a fixed-role specialist to finish his previous task.
Everyone on the team must constantly adapt so that we continue to maintain a constant and efficient flow of value… Fulfilling our shared responsibility of frequently delivering working software.
History Repeating?
An increasing number of organisations seem to recognize this, creating a demand for multi-skilled people. Interestingly, however, history seems to be repeating itself!
Up to the mid 1990s, high- and low-level software design was performed by systems analysts and then coded by programmers. Perhaps due to the demands of rapid application development, the roles later combined and the multi-skilled analyst-programmer emerged. Subsequently, this became the norm and analyst-programmers were thereafter known only as “developers.”
Today the title of developer-tester (or tester-developer) is emerging in response to the flexibility demanded by agile teams—kind of an analyst-programmer-tester. As the uptake of agile methods grows, this demand is only going to rise! If history indeed repeats itself, the developer-tester may, too, become the norm—negating the need for the “tester” suffix that differentiates them. Yes, the “software tester” job title, one of the few remaining titles derived from phased-development methods of old, could suffer the same fate as Ye Olde Systems Analyst.
This wouldn’t mean that software testing as a discipline will disappear altogether—just that many of the testers and developers of today will need to leave their comfort zones to become the developers of tomorrow.
Acquire ‘Tags’ or Badges – not a Job Title
Fixed, specialised job titles alone could be part of the problem. Maybe we need to stop linking specific roles to job titles. So often at conferences people ask the audience, “put your hand up if you are… analysts… programmers… testers… designers…”
I notice that many people will only put their hand up when one of these is called. You may notice me put my hand up for each of these roles. I think of these labels more like tags than titles. I feel I can tag myself with all of these roles and switch between them (to varying degrees of competency) as the situation demands.
Maybe they’re not so much like tags as badges. In some forces and certainly in the cadets and even among scouts and brownies, as you demonstrate new skills, you are entitled to wear new badges.
The difficulty with fixed-role thinking is that for many, their very identity is attached to their job titles. The challenge becomes showing people why they would want to broaden their thinking. I’m not sure I have time to address that in this particular post.
Maximise (your) Value
I can tell you what’s in it for me, personally. The tasks most relevant to my job-title may not be relevant to the team’s current story or goals. By dynamically switching roles, I am able to do the task that is the most relevant and valuable to the team at that time, within the context of the project’s goals, rather than just the tasks of most relevance to my job title. I am then able to accelerate the speed at which the team can clear each story, as the CQB team clears each room.
I recognise that this isn’t always immediately practical. Some teams are very protective over access to source code… but this is a matter of trust. There are many ways you can earn this trust… It may be that you need to demonstrate your abilities to manage your own git, mercurial or subversion repository before you’ll be given access to the relevant project repositories. It may be that you can demonstrate that you are able to build an open-source code-base using similar technology on your own. You may simply need to be able to talk about the right things while asking another team-member with a different area of expertise for help – demonstrating that you’ve at least understood the basics. So, one of the things outside your job-title that may add value to the team might be learning how to do something that the team will soon need doing.
So, hold on to your job titles and stick to your job descriptions if you choose. Personally, I’ve chosen to develop my individuality, embrace new skills and acquire new ‘tags’ & badges—bringing to the team more value, flexibility, throughput and opportunity.
References: [1] Ambler, Scott. “Generalizing Specialists: Improving Your IT Career Skills.” Agile Modeling, 2006. www.agilemodeling.com/essays/generalizingSpecialists.htm
To find out more about Airsoft or to take your colleagues on a similar journey to this article, check out http://firefight.co.uk. Tell them that this article sent you their way… they know who I am and have already taken one of my client’s teams on a similar journey.
Goal: What we’re trying to achieve which has one or more… Tasks: The high-level work-item that we complete to fulfil the goal, each having one or more… Actions: The specific steps or interactions we execute to complete the task.
I showed how many scenarios (acceptance tests) are pitched at too low a level. They’re often at the action level, detailing every field filled in and every button clicked. This is too low-level.
Instead, we want to express the business process… the tasks involved in fulfilling a goal. The actions should be expressed in the code (or step-definitions), not the plain-text scenarios. Pitching the scenarios at the action level makes scenarios much harder to maintain – especially when the user-interface changes. But, perhaps more importantly, they don’t express what’s of interest to the business.
Coverage vs. Speed tradeoffs of running scenarios through or below the GUI (respectively)
We’ve taken many of the lessons we’ve learned using BDD tools to address these problems and begun to distill the various heuristics and design ideas (patterns) that emerged into a single open-source extension to cucumber – cukesalad.
Many of the heuristics and design ideas expressed in the project can be used on your existing projects without using cukesalad:
Treat each step-definition as a class of task. Like other classes, have one file per step-definition and organise them so they’re easy to find. Name each file using the text used in the scenario.
Abstract the API that drives your application behind something representing the role or type of role involved in the story
Write scenarios like a narrative for someone in the role relevant to the user-story
Write the actions within the task (or step-definition) as if they’re instructions on how to complete that task
And more…
Cukesalad is the ongoing expression of us mercilessly refactoring a ‘typical’ Cucumber project. At the moment, it is more of an illustration of the concepts and ideas… but some are already using it on their day-to-day projects. Check it out… try it out… and let us know what you think.
Feature Injection, an approach to Agile Business Analysis created by Chris Matts, is a much misunderstood thing –. It is a way of combining several techniques to understand just enough of a business problem to start expressing solutions to it. It provides specific techniques to incrementally and iteratively comprehend each of the following:
The business value sought (the why)
The problem domain (what specifically needs solving to deliver that value)
The resulting roles, incentives and product capabilities (the solution)
Basically, it helps us to evolve everyone’s understanding of the business-need as we (by other means) also evolve the implementation of the product.
Now, before you say, “it’s nothing new”, Chris Matts will be the first to agree. He’s taken his experience of various techniques, combined several of them that often work, evolved it into an approach to agile business analysis and given it a name.
I wish I could explain all of this now, but we’ll have to save that for another day. This post is intended to try to explain the relationship between Feature Injection and User Stories.
I’ve seen several examples of user stories taking some inspiration from Feature Injection, however, I’m not sure any of them do Feature Injection enough justice.
A common story
One of the problems with how User Stories are often applied is that people focus on the role, the capability and then try to work out what the benefit is. This is quite natural, explained nicely by Udi Dahan:
Users ultimately dictate solutions to us, as a delta from the previous set of solutions we’ve delivered them. That’s just human psychology
– writer’s block when looking at a blank page, as compared to the ease with which we provide ‘constructive criticism’ on somebody else’s work
This is something that other aspects of Feature Injection actually help you to solve… but again, today I’m just focusing on user stories…
The tendency of people to dictate solutions, rather than the problem that needs solving, has lead some to emphasise that we should put the benefit of the story first. For example, let’s say a fictional printer manufacturer consistently entices 3% of everyone they e-mail, reminding them to check their ink-levels, to purchase print consumables. In this situation, some might illustrate taking a story like this…
As the PrintCo marketing manager
I want customers to register their e-mail addresses
So that we increase the sales of our print consumables
And changing it to this:
In order to increase the number of sales of our print consumables
As a marketing manager
I want customers to register their e-mail addresses
The intent behind this shuffling around is to get people to think about the problem in order of business value first, then the stakeholder then what the stakeholder thinks will deliver the value.
But, the story is talking about a stakeholder… In my experience, this doesn’t get the best value from the user story approach.
Stakeholder ‘stories’ or User Stories?
I’ve found that user stories are most useful when communicating to the team if they encourage a conversation around who the user is, what capability the user needs and why it’s important to the user (could that be why they are called “user stories”?). This helps us to understand what user experience they need and what capability will make that possible.
This template, brought to us by Rachel Davies and Tim McKinnon’s 2001 XP Day session “Tuning XP”, helps us with that:
As <some role>
I want <some capability>
So that <some benefit>
If we discuss this solely from the business stakeholder’s point of view, the team doesn’t get as much understanding from what is needed by the user or why the user will need this capability. If the capability summarises what the product will enable or do for user it’s a lot easier to see what needs to be changed in the product. The benefit should be the answer to “what’s in it for the user?” or “why would they want the product to do that?” (exploring the persona of the user is helpful in finding this out).
So, taking the earlier PrintCo example, an alternative way of writing the user story would be like this:
As a PrintCo Customer
I want to be prompted to share my e-mail address with PrintCo
So that I can avoid those times when I need to print something but the ink is empty
Ah… but now we’re back where we started – where’s the business value? How do we get people to think about the business value first and then identify the roles and capabilities?
Let’s start again
Ideally, we want the benefit of driving the features from the business value and the increased understanding of what we’re implementing by understanding the user in our conversations around a user story.
To get to the right place, we need to start again with our example. Imagine that, instead of the above, we’d taken a different approach.
Recall that the business value or goal was:
Increase PrintCo printer cartridge sales by increasing our customer mailing list
Then, we could consider what behaviour we want to encourage and for whom. For example, we want the Customer to share their e-mail address with us online.
So, what will encourage that behaviour… What’s in it for our users? Into our business value statement, we “inject” the beginnings of a capability (or feature) that will help us deliver the value:
In order that PrintCo printer cartridge sales go up by growing the mailing list:
As a PrintCo Customer
I want <something>
So that an e-mail reminder helps me to avoid those times when I need to print something but the ink is empty
Now we’re ready to talk about the special <something> that we don’t currently have that will give the user the benefit they want:
In order that PrintCo printer cartridge sales go up by growing the mailing list:
As a PrintCo Customer
I want to be prompted for my e-mail address
So that an e-mail reminder can help me avoid those times when I need to print something but the ink is empty
We also want the Customer Services Rep to be encouraged to ask customers for their e-mail address when dealing with customers over the phone. So, we inject some more features:
In order that PrintCo printer cartridge sales go up by growing the mailing list:
As a PrintCo Customer
I want to be prompted for my e-mail address
So that an e-mail reminder can help me avoid those times when
I need to print something but the ink is empty
As a PrintCo Customer Services Rep
I need <something>
So that I increase the points I get for e-mail captures, improving my
position on the high-scores display
As a PrintCo Customer Services Rep
I need <something>
So that I can see that the points I earn for e-mail captures affect my
position on the high-scores display
And now we want to know what that special something is going to be for our Customer Services Rep:
In order that PrintCo printer cartridge sales go up by growing the mailing list:
As a PrintCo Customer
I want to be prompted for my e-mail address
So that an e-mail reminder can help me avoid those times when I need
to print something but the ink is empty
As a PrintCo Customer Services Rep
I need to be prompted to ask for the customer’s e-mail address
So that I increase the points I get for e-mail captures, improving my
position on the high-scores display
As a PrintCo Customer Services Rep
I need e-mail captures shown as one of the columns on the high-scores display
So that I can see that the points I earn for e-mail captures affect my
position on the high-scores display
And, if it is important that you capture the key stakeholder:
In order that the Marketing Manager grows PrintCo printer cartridge sales by growing the mailing list…
Or, you don’t need to even use ‘In order to’… you can word it any way you like
Goal: the Marketing Manager wants to grow PrintCo printer cartridge sales by growing the mailing list…
The most important thing here is not the wording. It’ that we find a way of keeping the business value in the conversation and when we’re talking about the capabilities, we focus on the user. What I’ve described is just one way of achieving that.
It’s like a “theme” for the stories
Themes have been suggested by many as a way of grouping user stories. In this case, the ‘In order to…’ can be thought of as a theme for the stories – i.e. the theme is described in terms of business value. Stories, described in terms of the user capability and incentive/context, are injected into the “theme” as we identify roles and capabilities that deliver the business value.
Notice, that I thought about the “As a…” and “So that…” aspects of the user story first and then summarised the capability, yet the order in which I expressed them remained as normal. As Rachel Davies once highlighted to me, just because we think of these things in one order, that may not be the best order for a discussion with the people who will implement it.
Another way of putting this is that the “As a… I want… So that…” is optimised for the conversation that helps the product owner(s) communicate what is required to the rest of the team, not for the order in which we generally discover the information.
In Summary
As you can see, Feature Injection doesn’t encourage you to simply move the “So that” to the beginning and reword it with “In order to”. I can see why people do that. One possible reason is because the stakeholder intent has been mashed into a user story, but that loses the purpose of a user story. I can also see why that happens, because there wasn’t an obvious place to think or talk about stakeholder intent. Business-value focused themes give us that.
I hope this helps clarify a little about Feature Injection and how it relates to user stories… but remember, this is only the tip of the Feature Injection iceberg. Actually it’s just one of the outcomes of Feature Injection. Watch this space for more.
Today, I came across this post by Ryan Bigg where he talks of the pains he’s experienced with Cucumber.
Fortunately for Ryan, the outcome was a positive one, he ended up finding what appears to be a nice looking API for automating test-execution.
The experience he had with Cucumber, however, is a common one. Often teams start using Cucumber in an effort to reduce the need for programming skills when writing automated tests.
This isn’t the problem that Cucumber and other BDD tools are trying to solve and this is why so many teams who misuse it in this way experience difficulty and frustration.
BDD tools like Cucumber are designed to help teams and their customers arrive at a shared understanding of the problem they wish to solve (in terms of the user’s goals and tasks). It’s not really intended to describe the solution (i.e. step-by-step interactions with the GUI).
If your Cucumber scenarios have words such as “click” or “type” or mention field names and the like, it’s probable that you’re either:
a) Using Cucumber to automate test-execution (not what it was intended for) or
b) Trying to do BDD but writing the scenarios at too low a level of detail.
If what you’re doing is (a) then the post I wrote over the weekend might help you go down a path where automating your tests will make the transition to BDD that much easier.
If you really, really only want to automate test-execution then you might find that you’re putting Cucumber where it’s not supposed to go… and just so you know – that’s probably going to hurt 🙂
There’s something wrong with many behaviour specs (or acceptance tests). It’s been this way for some time. I’ve written about this once or twice before, referencing this post by Kevin Lawrence from 2007.
So, first things first, I want to take this opportunity to update the terminology I use…
Goals -> Tasks -> Actions
A useful technique used in User-Centred Design (UCD) and Human Computer Interface (HCI) design is Task Analysis. There are three layers of detail often talked about in Task Analysis:
Goal: What we’re trying to achieve which has one or more… Tasks: The high-level work-item that we complete to fulfil the goal, each having one or more… Actions: The specific steps or interactions we execute to complete the task.
Previously, the terms used by Kevin, myself (and several others) were Goal->Activities->Tasks. From now on, I’m going to use the UCD/HCI/Task Analysis terms Goal->Task->Action. It’s exactly the same model – just with different labels at the three layers of detail.
What’s wrong with your average behaviour spec?
Let’s look at a common example… The calculator. For convenience, I’m going to borrow this one from the cucumber website[1].
Scenario: Add two numbers
Given I have entered 10 into the calculator
And I have entered 5 into the calculator
When I press add
Then the result should be 15 on the screen
[1]note: I’m using this example for convenience and simplicity. The value of the example on the cucumber website is to demonstrate how easy cucumber is to use and not necessarily as an exemplar feature spec
What would you say the scenario’s name and steps are representing? Goals and Tasks or Tasks and Actions?
I’d argue that adding two numbers is a task and the steps shown above are actions.
Instead, I try to write the spec (or test) with a scenario-specific goal and the steps as tasks.
Scenario: sum of two numbers
When I add 10 and 5
Then I should see the answer 15
I.e.: Scenario: <A scenario specific goal>
Given <Something that needs to have happened or be true>
When <Some task I must do>
Then <Some way I know I've achieved my goal>
Another Typical Example
Let’s apply this to another typical example that might be closer to what some people are used to seeing:
Scenario: Search for the cucumber homepage
Given I am at http://google.com
When I enter "cucumber" into the search field
and click "Search"
Then the top result should say "Cucumber - Making BDD fun"
Again this is talking in terms of actions. As soon as I’m talking in terms of click, enter, type or other user-action, I know I’m going into too much detail. Instead, I write this:
Scenario: Find the Cucumber home page
When I search for "Cucumber"
Then the top result should say "Cucumber - Making BDD fun"
Why does it matter?
In the calculator example, the outcome the business is interested in for the first scenario is that we get the correct sum of two numbers. The steps in the scenario should help us arrive at a shared understanding of what ‘correct’ means. How we solve the problem of getting the numbers into the calculator and choosing the operator is a separate issue. That’s detail we can defer. It may be better to explore the specifics of the workflow using, sketches, conversation, wire-frames or by seeing and using our new calculator.
So, expressing our scenarios in terms of goals and tasks helps the delivery team and the business arrive at a shared understanding of the problem we’re trying to solve in that scenario.
Expressing the scenario in terms of the clicks, presses and even fields we’re typing into is focusing on a solution, not the problem we’re trying to solve.
But there’s another benefit to doing it this way…
A Practical Concern – Maintainability
The first calculator example follows reverse-polish notation for the sequence of actions:
enter the first number
enter the second number
press add
If we put that detail in the scenarios, that workflow will be repeated everywhere – for addition, subtraction, division, multiplication… and anywhere any calculation is described.
What happens if the workflow for this calculator (such as the UI or API) changes from a reverse-polish notation to a more conventional workflow for a calculator? Like this:
enter the first number
press add
enter the second number
press equals
The correct answer hasn’t changed – i.e. the ‘business rule’ is the same – it’s just the sequence of actions has changed.
Now we have to go through all the feature files and update all the scenarios. In the case of our calculator that may only be a few files covering add, subtract, divide, multiply. For something larger and more complex this could be a lot of work.
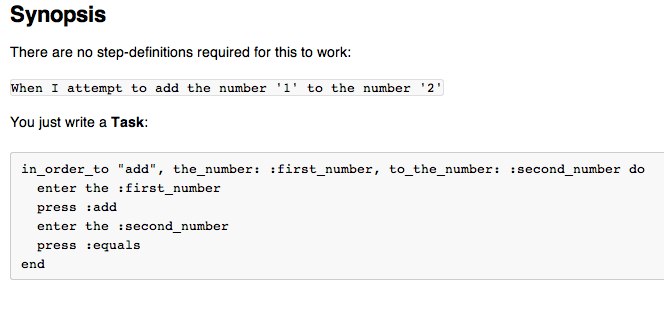
Instead, putting this in the code of the step-definition means that this:
When ^I (add|subtract|divide|multiply) (.*) (?:and|from|by)? (.*) do |operator, first_number, second_number|
@calc = @calc ||= Calculator.new
@calc.enter first_number
@calc.enter second_number
@calc.send operator.to_sym
end
Would have to change to this:
When ^I (add|subtract|divide|multiply) (.*) (?:and|from|by)? (.*) do |operator, first_number, second_number|
@calc = @calc ||= Calculator.new
@calc.enter first_number
@calc.send operator.to_sym #moved up from the bottom
@calc.enter second_number
@calc.calculate #new action for the conventional calculator workflow
end
Nothing else would need to change – other than the product of course. By writing the steps as tasks, all of our feature files would still accurately illustrate the business rule even though the workflow of the interface (gui or api) has changed.
Taking your scenario-steps to task
So, taking this approach helps us to reduce our maintenance overheads. Putting the Actions inside the step definition makes our tests less brittle. When the workflow changes we only need to update our specs in one place – the step-definitions.
Of, perhaps, greater importance – by capturing the user’s scenario-specific goal as the scenario name and the tasks as the steps, the team are working towards a shared understanding of the part of the problem we’re trying to solve not a solution we might be prematurely settling upon. When rolled up with the broader context (expressed in the user-story and its other scenarios) it gives us a focus on solving the wider problem rather than biasing the solution.
Sometimes, at first, it’s hard to see how to express the scenario and is easier when people start by talking of clicks, presses and what they’re entering. And that’s ok. Maybe that’s where the team needs to start the conversation. Just because that’s where you start, ask “why are we doing those actions” a few times, and it doesn’t have to be where you end up.
This was originally posted on my old blog on 10th April 2010
Recently, I wrote about my views on using and estimating with task-cards. I highlighted that tracking progress with burn-up/down charts showing effort completed/remaining is not a true measure of progress, especially if we subscribe to the idea that we measure progress with working-software.
I also highlighted how tasks “horizontally slice” a “vertically sliced” story.
There are some specific points I’ll be answering on infoq, but some general points are more easily answered here…
True measures of progress
One of the key points I was trying to make in my first post (linked to above) is that if “working software” is our measure of progress then tracking task completion is not consistent with that.
One of the problems task-hours are trying to solve is to provide a visible indication of progress. It’s also something that many people find easier to understand. The idea of relative-points estimation seems to baffle many people when they first encounter it.
In my original post (linked above) I referenced an approach, blogged about by Jason Gorman, outlining a solution to providing a visible indication of progress that is compatible with the idea of measuring progress with working software. It also works more seamlessly with the solution of measuring throughput trends of the team (e.g. with story points) so that the team can estimate how much can be done in the next iteration.
Value Points & Task Points
Value points were mentioned in the infoq comments. Value points are solving a different problem and don’t help the team estimate what can be done. The value of a story isn’t an indication of its complexity. Value, combined with complexity points, can help determine priorities. Arlo Belshey explains some interesting views on this.
Prioritisation is, in my view, one of the few reasons to place some sort of estimate on value & complexity. Unfortunately, it seems to be often used to establish a contract with the team for when something will be done and apply pressure when the estimates turn out to be inaccurate.
Non-estimating pull systems
My preference is to use such estimates only for prioritisation… after that, things just take as long as they take. There is some benefit in tracking accuracy trends so that we can learn from them, however, spending too much time on these things simply slows down the process of getting things done. Interestingly, I have not yet seen the business be quite so passionate about evaluating whether their value estimates were accurate when the product makes it to the real world. Funny that.
Instead, I prefer to leave estimation behind once we’ve prioritised things and pull stories or customer valued work items through the system without using previous estimates to predict their completion date. With the way that most budgets are determined and allocated, this idea isn’t compatible with the way much of the business world works. For pull systems that eliminate estimation as a means of predicting the future to work (such as Kanban), we need a more adaptive approach to budgetary spend. Business needs to find a way to adapt budget allocation more frequently, perhaps as frequently as monthly, perhaps more frequently still. The business now needs to look at how it can respond to change rather than focus on following a budget-plan.
Business-world: now it’s your turn
Budget holders now need to be more agile. We, those who evolve the implementation of the ideas of the business, have responded to their demands to be able to respond to rapidly changing markets and provide that competitive edge. For the more mature implementation teams, the hindrance now is no longer how we make the products, but the business culture of inflexible and predictive budget allocation.
This originally appeared on my old blog on 16th March 2010…
Others have talked about the virtues of stories as vertical slices of a problem (end-to-end capabilities) rather than horizontal slices (system layers or components). So, if we slice the problem with user stories, how do we slice the user-stories themselves?
If, as I sometimes say, acceptance tests (a.k.a. examples/scenarios/acceptance-criteria) are the knife with which we slice a story into even thinner vertical slices, then I would say my observation of ‘tasks’ is that they are used as the knife used to cut a story into horizontal slices. This feels wrong…
Sometimes I also wonder, hasn’t anyone else noticed that the idea of counting the effort of completed tasks on burn-down/up charts is counter to the value that we measure progress only with working software? Surely it makes more sense to measure progress with passing tests (or “checks” – whichever you prefer).
These are two of the reasons I’ve never felt very comfortable with tasks, because:
they’re often applied in such a way that the story is sliced horizontally
they encourage measuring progress in a less meaningful way than working software
Tasks are, however, very useful for teams at first. Just like anything else we learn how to do, learning how to do it on paper can often help us then discard the paper and do the workings in our heads. However, what I’ve noticed is that most teams I’ve worked with continue to write and estimate tasks long after the practice is useful or relevant to them.
For example, there comes a time for many teams where tasks become repetitive. “Add x to the Model”, “Change View”… and so on. Is this adding value to the process or are you just doing it because the process says you should do it?
Simply finding that your tasks are repetitive doesn’t mean the team is ready to stop using them. There is another important ingredient, meaningful acceptance criteria (scenarios / acceptance-tests / examples).
I often see stories with acceptance criteria such as:
Must have a link to save the profile
Must have a drop down to select business sector
Business sector must be mandatory
…
Although these are “acceptance criteria” they aren’t what we mean by acceptance criteria in the context of user stories. Firstly, they are talking about how the user interacts rather than what they need to achieve (I’ve talked about this before). Secondly, they aren’t examples. What we want are the variations that alter the behaviour or response of the product:
Should create a new profile
Profile cannot be saved with blank “business sector”
So, if you are using tasks, consider an alternative approach. First, look at your acceptance criteria, make sure they are more like examples and less like instructions. Once that’s achieved, consider slicing each criterion (or scenario) horizontally with the tasks rather than the story. Pretty soon, you’ll find that you don’t need tasks anymore and you can simply measure progress in terms of the new capabilities you add to your product.
Software is about the only industry one of the few industries that lumps testing and QA under one banner. It’s one of those things where common misuse of a term results in the community changing it’s meaning… this happens in mainstream language all the time.
Testing something is actually more analogous to quality control or, QC , [although it isn’t quality control].
QA is more concerned with the process – collecting information about the performance of the process in order to determine if we are ‘assuring’ (or more realistically increasing the probability of) quality. Statistical information about problems found in the product (during quality control) is just one of many pieces of info useful to someone concerned with QA (which really should be the whole project team)
In short:
QC helps us answer the question ‘does our product work?’
QA helps us answer the question ‘does our process work?’
Unfortunately, in the software industry, all too many teams don’t realise their process doesn’t work until the testers find all the ways in which the product doesn’t work… maybe that’s why software testing has come to be known as QA.
In “You’re Cuking it Wrong”, Jonas Nicklas, shows several examples of bad scenarios (or acceptance tests whichever term you prefer) and demonstrates better approaches. This is an excellent post on common mistakes made when writing example scenarios with Cucumber.
I think, however, he could have gone further in one case. One of his examples of a bad scenario looks like this:
Scenario: Adding a subpage
Given I am logged in
Given a microsite with a Home page
When I click the Add Subpage button
And I fill in "Gallery" for "Title" within "#document_form_container"
And I press "Ok" within ".ui-dialog-buttonpane"
Then I should see /Gallery/ within "#documents"
(Dude – yep, seen these… I agree… not good). He goes on to suggest it should really look like this:
Scenario: Adding a subpage
Given I am logged in
Given a microsite with a home page
When I press "Add subpage"
And I fill in "Title" with "Gallery"
And I press "Ok"
Then I should see a document called "Gallery"
This is a massive improvement. It keeps the specifics that inform the reader and give them some context (like filling in the “Title” with “Gallery”) and takes them further away from the implementation. Although it gets closer to expressing customer intent, I think it could go further. At the moment, it is describing the ‘what’ and some of the ‘how’. This example makes complete sense if what we are exploring is the design of the UI. I’ve not found these scenarios to be a good place to do that, however.
Instead, in these specifications we want our examples to illustrate the customer intent. The ‘what’ not the ‘how’. There are other places we can capture the ‘how’ – i.e. in the step methods.
Instead, I would write it like this:
Scenario: Adding a subpage
Given a microsite with a home page
Given I am logged in
When I Add a Subpage with a Title of "Gallery"
Then I should see a document called "Gallery"
I’ve removed all the “Tasks” and left only “Activities”. This leaves the user experience completely open. This ensures that when there are UI changes, I only change the code that performs the tasks (clicking, pressing, etc.) and my scenarios evaluate whether the customer intent is still fulfilled – without having to go back and change a lot of files.
Otherwise – great post Jonas 🙂
Thinking through writing… on innovation, business, technology and more